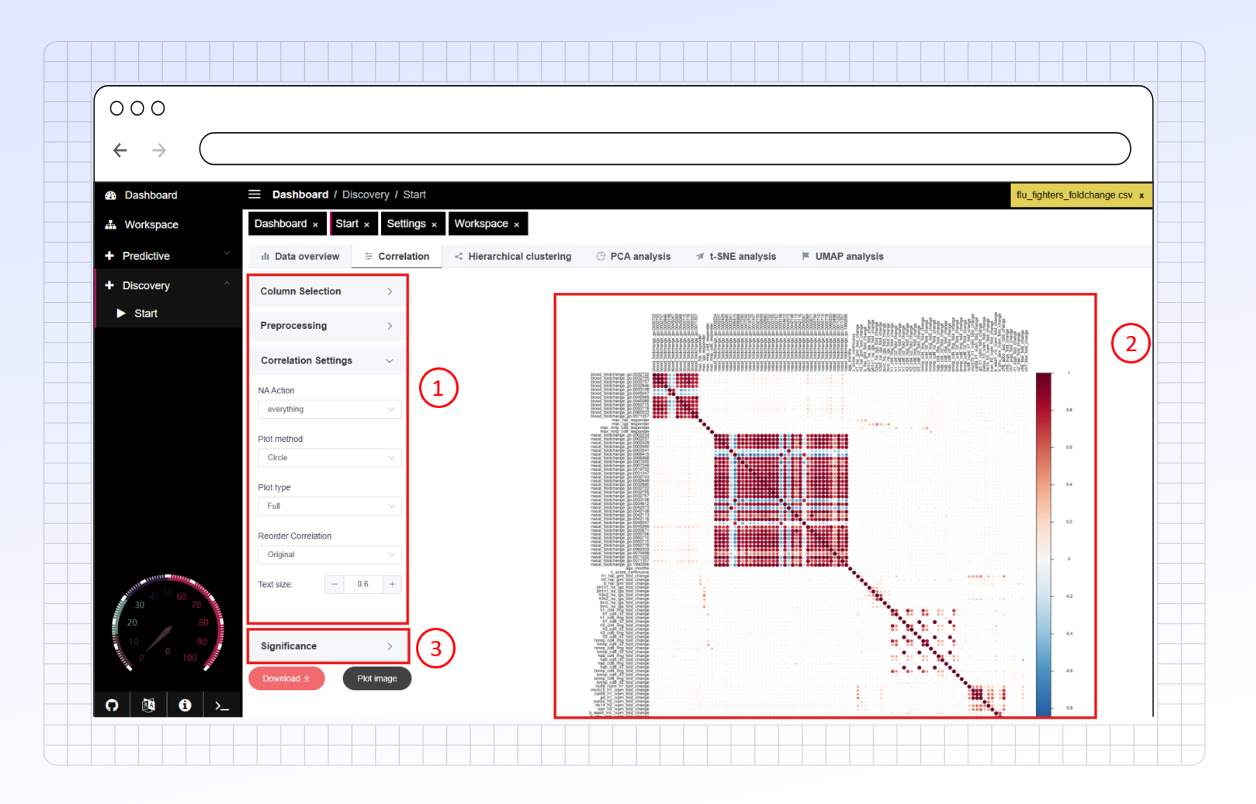


This plot shows correlations between a small number of variables. You can easily see strong positive correlations (large dark red circles) between max_hai_responder and max_iga_responder, and weaker negative correlations (small light blue circles) like between max_hai_responder and h3_v0_seropositive.

Correlogram handles datasets with many variables effectively. For instance, this example shows how it can reveal distinct blocks of highly correlated variables, which appear as clusters of dark red circles. Such patterns might suggest related genes or biomarkers. You'll also notice areas with minimal correlation, indicated by very small, pale circles.

In this plot, correlations deemed not statistically significant (at the chosen alpha level, potentially after BH adjustment) are marked with a cross (X). This uses the pch setting for Insignificant Action.

This plot visualizes both the correlation (color/size) and its confidence interval. Here, the CI Plotting Method might be set to square or a similar option, where the shape or additional elements represent the calculated interval around the correlation estimate. The specific appearance depends on the chosen method.